
Building Faceted Search using Elasticsearch
Faceted search
Faceted search is a type of search that enables users to narrow down search results by applying multiple filters based on predefined facets, which are categorical attributes or properties of the items being searched. This method is particularly useful on e-commerce platforms, as it enhances the user experience by allowing users to efficiently refine their search queries based on specific criteria and preferences.
Below is an example of a faceted search interface for a query like ‘phone’ on Amazon:
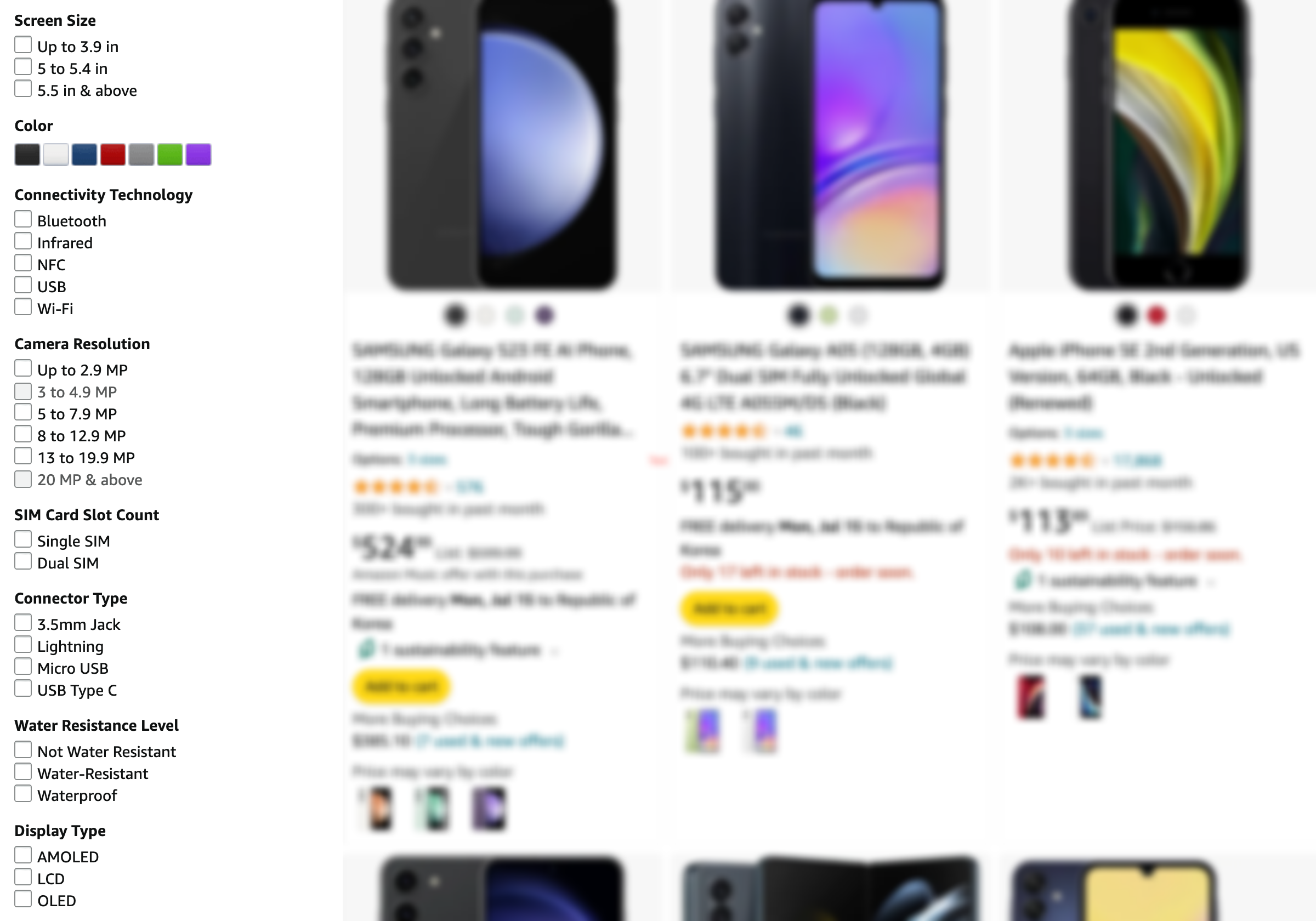
In the picture above, the left pane shows available facets based on the items being searched. Clicking on any of the values in the facets will narrow down results accordingly. Therefore, a faceted search system’s functions can be broadly divided into two categories as below:
- Getting facet distribution: Gathering and organizing data to provide users with a comprehensive overview of the facet distribution of items being searched.
- Searching by facets: Narrowing down search results based on specific facets.
In this post, I will explain how to build a faceted search using Elasticsearch, which is a document-oriented database.
I will also use the Kibana Console to interact with Elasticsearch.
The specific versions of Elasticsearch and Kibana in this tutorial are both 8.13.4.
Relational database vs document-oriented database
Faceted search can indeed be built using a relational database. However, it is more common to use a document-oriented database like Elasticsearch for several reasons:
- Performance: Relational databases are not inherently optimized for the complex, multi-dimensional queries typical of faceted search. This can lead to slow response times and high computational costs. Elasticsearch, on the other hand, is designed for such scenarios, providing faster query performance.
- Scalability: Elasticsearch scales more effectively horizontally, allowing it to handle large volumes of data and high query loads more efficiently than relational databases.
- Full-text search: Faceted search is often used with full-text search, an area where relational databases fall short.
For these reasons, leveraging a document-oriented database like Elasticsearch is often the preferred choice for implementing faceted search.
Modeling data
The faceted search system we are about to build is for an e-commerce platform where a product can have multiple facets and a facet can have multiple values, like the example above. For instance, a phone can have facets like color or capacity, where color can have values such as “black” or “red” and capacity can have values such as “128GB” or “256GB”.
The relationships among product, facet, and value would be described as follows:

Defining fields
First, we are going to have a facets field to store all facets data.
Note that while we could explicitly define fields for every possible facet, such as color, capacity, or any other specific attribute, there is no need for such specific fields in this schema.
Defining fields explicitly for every attribute would make the schema rigid and difficult to manage as the number of product attributes increases.
Instead, we use a flexible approach by implementing generic facets.
This allows us to dynamically handle a wide variety of product attributes without altering the schema structure.
By leveraging nested fields within the facets property, we can accommodate any number of attributes, providing a scalable and adaptable solution.
This approach not only simplifies the indexing process but also ensures that our search system can evolve with the product catalog, accommodating new attributes seamlessly as they arise.
The facets field will contain a list of facets, each of which has code, name, and values.
The values will contain a list of values, each of which has code and name.
A value here is like an option or attribute associated with the facet.
The reasons for assigning code to name are as follows:
- Uniqueness: Codes ensure that each facet can be uniquely identified, avoiding any ambiguity that might arise from identical names. For example, capacity might refer to the storage capacity of a digital device (e.g., 128GB) or the volume capacity of a bottle (e.g., 500ml).
- Consistency: Codes allow for consistent reference to facets across different systems and interfaces, making integrations and communications more reliable. This also helps in internationalization where multiple languages should be supported without changing the underlying schema.
- Efficiency: Using codes can be more efficient for storage and processing, especially in large datasets where names might be longer and more variable.
Using id intead of code is also possible if the primary use case is for internal referencing only.
I only choose code to open for more human-readable or descriptive string identifier.
Additionally, the index will also have id and name fields to reflect a real-world application.
Defining field data types
The id is a unique identifier of a document (or product), so it should be of keyword type.
The name is the name of a product and should be of text type for full-text search.
The facets should be of nested type for handling multiple attributes associated with each product.
The values should be of nested type too.
Inside facets and values, the type of the name and code properties are defined as keyword, which is suitable for filter operations, aggregations, and exact matches.
As a result, the index has three properties:
id(keyword)name(text)facets(nested)code(keyword)name(keyword)values(nested)code(keyword)name(keyword)
Defining mapping
Below is the complete JSON mapping for our Elasticsearch index::
{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"facets": {
"type": "nested",
"properties": {
"code": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"values": {
"type": "nested",
"properties": {
"code": {
"type": "keyword"
},
"name": {
"type": "keyword"
}
}
}
}
}
}
}
}
Running Elasticsearch locally
Skip this section unless you want to run Elasticsearch to follow this tutorial in your local environment.
You can run Elasticsearch in your local environment by using Docker Compose. Follow the steps to run Elasticsearch and Kibana:
- Save the compose file in your directory.
- Run
docker-compose upin the same directory to run Elasticsearch and Kibana. - Open your web browser and navigate to http://localhost:5601, which is the Kibana URL.
- Log in with the the following credentials:
- Username:
elastic - Password:
elasticpassword
- Username:
- Click on
Dev Toolsin theManagementsection in the side navigation menu.
If everything is done successfully, you should see the Console application:
This will provide an interactive interface where you can send requests to Elasticsearch.
Creating index
To create an index named products, go the the Kibana Console and send the PUT request to the /products path with the mappings we defined:
PUT /products
{
"mappings": {
"dynamic": "strict",
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"facets": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"code": {
"type": "keyword"
},
"values": {
"type": "nested",
"properties": {
"name": {
"type": "keyword"
},
"code": {
"type": "keyword"
}
}
}
}
}
}
}
}
If you see the following response, the index has been successfully created:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "products"
}
Inserting documents
The following tables provide example products and facets for demonstration::
Products:
| id | name | facets |
|---|---|---|
| 1 | Phone 1 | (Black), (128GB) |
| 2 | Phone 2 | (Red), (256GB) |
| 3 | Phone 3 | (Black, Red), (128GB, 256GB) |
| 4 | Phone 4 | (Black, Blue), (256GB, 512GB) |
Facets:
| code | name |
|---|---|
| 1 | color |
| 2 | capacity |
Color:
| code | name |
|---|---|
| 1 | Black |
| 2 | Red |
| 3 | Blue |
Capacity:
| code | name |
|---|---|
| 1 | 128GB |
| 2 | 256GB |
| 3 | 512GB |
Let’s insert the documents with the following JSON requests:
POST /products/_doc
{
"id": "1",
"name": "Phone 1",
"facets": [
{
"name": "color",
"code": "1",
"values": [
{
"name": "Black",
"code": "1"
}
]
},
{
"name": "capacity",
"code": "2",
"values": [
{
"name": "128GB",
"code": "1"
}
]
}
]
}
POST /products/_doc
{
"id": "2",
"name": "Phone 2",
"facets": [
{
"name": "color",
"code": "1",
"values": [
{
"name": "Red",
"code": "2"
}
]
},
{
"name": "capacity",
"code": "2",
"values": [
{
"name": "256GB",
"code": "2"
}
]
}
]
}
POST /products/_doc
{
"id": "3",
"name": "Phone 3",
"facets": [
{
"name": "color",
"code": "1",
"values": [
{
"name": "Black",
"code": "1"
},
{
"name": "Red",
"code": "2"
}
]
},
{
"name": "capacity",
"code": "2",
"values": [
{
"name": "128GB",
"code": "1"
},
{
"name": "256GB",
"code": "2"
}
]
}
]
}
POST /products/_doc
{
"id": "4",
"name": "Phone 4",
"facets": [
{
"name": "color",
"code": "1",
"values": [
{
"name": "Black",
"code": "1"
},
{
"name": "Blue",
"code": "3"
}
]
},
{
"name": "capacity",
"code": "2",
"values": [
{
"name": "256GB",
"code": "2"
},
{
"name": "512GB",
"code": "3"
}
]
}
]
}
After indexing all four documents, you can retrieve all documents from the products index with the request below:
GET /products/_search
{
"query": {
"match_all": {}
}
}
The response JSON should look something like this. (Since the full JSON response is quite extensive, I thought it’d be better to provide an external link rather than including it on this page or using a collapsible section to avoid disrupting the post.)
Getting facet distribution
In order to get the facet distribution, you need to use Elasticsearch’s aggregation function. Below is the query DSL for it:
GET /products/_search
{
"size": 0,
"aggs": {
"facets": {
"nested": {
"path": "facets"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.code"
},
"aggs": {
"names": {
"terms": {
"field": "facets.name"
}
},
"values": {
"nested": {
"path": "facets.values"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.values.code"
},
"aggs": {
"names": {
"terms": {
"field": "facets.values.name"
}
}
}
}
}
}
}
}
}
}
}
}
The aggregations object from the response JSON can be found here.
I want to mention that you don’t necessarily set the size to 0 if you are performing the search and aggregation at once.
It’s just to get the facet distribution, not the search results.
Breakdown
A query DSL below aggregates on facets.code only:
GET /products/_search
{
"size": 0,
"aggs": {
"facets": {
"nested": {
"path": "facets"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.code"
}
}
}
}
}
}
The aggs object contains the main aggregation with a nested path to facets, which is a terms aggregation on facets.code.
This will create buckets based on the unique values of facets.code.
The aggregations object from the response JSON would be as follows:
{
"aggregations": {
"facets": {
"doc_count": 8,
"codes": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "1",
"doc_count": 4
},
{
"key": "2",
"doc_count": 4
}
]
}
}
}
}
But we do not know the corresponding facet names yet.
To retrieve the facet names, we will add a sub-aggregation on facets.name within a facets.code aggregation.
A sub-aggregation allows you to further break down the results for each bucket of documents.
Here’s the query DSL for it:
GET /products/_search
{
"size": 0,
"aggs": {
"facets": {
"nested": {
"path": "facets"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.code"
},
"aggs": {
"names": {
"terms": {
"field": "facets.name"
}
}
}
}
}
}
}
}
The aggregations object from the response JSON is as follows:
{
"aggregations": {
"facets": {
"doc_count": 8,
"codes": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "1",
"doc_count": 4,
"names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "color",
"doc_count": 4
}
]
}
},
{
"key": "2",
"doc_count": 4,
"names": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "capacity",
"doc_count": 4
}
]
}
}
]
}
}
}
}
Now we have the facet distribution by code and name.
Since all facets.code values are unique and mapped to names in a 1:1 relationship in our scenario, the size of the facets.name buckets must be exactly 1.
In other words, if a facet code has multiple names (e.g., two names), the size of the buckets for those names should match the number of names (e.g., 2).
Like so, another nested aggregation is performed on facets.values which further breaks down into terms aggregations on facets.values.code:
GET /products/_search
{
"size": 0,
"aggs": {
"facets": {
"nested": {
"path": "facets"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.code"
},
"aggs": {
"names": {
"terms": {
"field": "facets.name"
}
},
"values": {
"nested": {
"path": "facets.values"
},
"aggs": {
"codes": {
"terms": {
"field": "facets.values.code"
}
}
}
}
}
}
}
}
}
}
Lastly, just as including a sub-aggregation on facets.name, adding a sub-aggregation on facets.values.name within the facets.values.code finalizes the query for getting facet distribution with all names and codes mapped together.
Sorting
You can also sort the values by a specific metric such as count or alphabetical order.
Here’s an example of how you can sort the values by count in ascending order:
"terms": {
"field": "facets.values.code",
"order": {
"_count": "asc"
}
}
And here’s an example of how you can sort the values by alphabetical order:
"terms": {
"field": "facets.values.code",
"order": {
"_key": "asc"
}
}
Size
The default size of a bucket is 10. Here’s an example of how you can increase the size to 20:
"terms": {
"field": "facets.values.code",
"size": 20
}
Now we know how to obtain facet distribution using Elasticsearch. However, the responses from Elasticsearch might not be suitable for rendering in a faceted search interface on the UI, as they often contain raw, nested data structures and metadata. Therefore, it is advisable to transform these responses into a more user-friendly format.
For example, the aggregations part of the response can be transformed into a simpler, more understandable structure like the following JSON:
[
{
"key": "1",
"name": "color",
"count": 4,
"values": [
{
"key": "1",
"name": "Black",
"count": 3
},
{
"key": "2",
"name": "Red",
"count": 2
},
{
"key": "3",
"name": "Blue",
"count": 1
}
]
},
{
"key": "2",
"name": "capacity",
"count": 4,
"values": [
{
"key": "2",
"name": "256GB",
"count": 3
},
{
"key": "1",
"name": "128GB",
"count": 2
},
{
"key": "3",
"name": "512GB",
"count": 1
}
]
}
]
The following Python code will help transform the response into a format like the example above:
from elasticsearch import Elasticsearch
elasticsearch = Elasticsearch(ES_HOST)
body = {
"size": 0,
"aggs": {
"facets": {
"nested": {"path": "facets"},
"aggs": {
"codes": {
"terms": {"field": "facets.code"},
"aggs": {
"names": {"terms": {"field": "facets.name"}},
"values": {
"nested": {"path": "facets.values"},
"aggs": {
"codes": {
"terms": {"field": "facets.values.code"},
"aggs": {"names": {"terms": {"field": "facets.values.name"}}},
}
},
},
},
}
},
}
},
}
response = elasticsearch.search(index="products", body=query)
facet_distribution = []
for facet_bucket in response["aggregations"]["facets"]["codes"]["buckets"]:
facet = {
"key": facet_bucket["key"],
"name": facet_bucket["names"]["buckets"][0]["key"],
"count": facet_bucket["doc_count"],
"values": [],
}
for value_bucket in facet_bucket["values"]["codes"]["buckets"]:
value = {
"key": value_bucket["key"],
"name": value_bucket["names"]["buckets"][0]["key"],
"count": value_bucket["doc_count"],
}
facet["values"].append(value)
facet_distribution.append(facet)
This way, the data becomes easier to understand and use in your faceted search interface.
Searching by facets
First, let’s search for products with black color.
The following query DSL searches for documents with the facet code 1 which is color and the value code 1 which is black:
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "1"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"1"
]
}
}
}
}
]
}
}
}
}
]
}
}
}
The response JSON would look something like this.
It has retrieved three documents with the black value in their color facet.
Below is the table version of the response JSON for the sake of readability:
| id | name | facets |
|---|---|---|
| 1 | Phone 1 | (Black), (128GB) |
| 3 | Phone 3 | (Black, Red), (128GB, 256GB) |
| 4 | Phone 4 | (Black, Blue), (256GB, 512GB) |
Conjunctive facets
Conjunctive facets, also known as regular facets, allow users to filter search results by multiple criteria simultaneously using “AND” logic.
For example, the query DSL below searches for products which have the black for color facet and 512GB for digital capacity facet:
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "1"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"1"
]
}
}
}
}
]
}
}
}
},
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "2"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"3"
]
}
}
}
}
]
}
}
}
}
]
}
}
}
This time, the response will contain one document with red and 256GB in its facets:
| id | name | facets |
|---|---|---|
| 4 | Phone 4 | (Black, Blue), (256GB, 512GB) |
Disjunctive facets
Disjunctive facets use “OR” logic.
For example, the query DSL below searches for documents whose color is either red or blue:
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "1"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"2",
"3"
]
}
}
}
}
]
}
}
}
}
]
}
}
}
The response will contain three documents with red or blue as their color facet:
| id | name | facets |
|---|---|---|
| 2 | Phone 2 | (Red), (256GB) |
| 3 | Phone 3 | (Black, Red), (128GB, 256GB) |
| 4 | Phone 4 | (Black, Blue), (256GB, 512GB) |
In some scenario where you might want to search products with different facets using OR logic, you can use should instead of must in the query DSL.
For example, the query DSL below searches documents whose color is black or capacity is 512GB:
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "1"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"1"
]
}
}
}
}
]
}
}
}
},
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "2"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"3"
]
}
}
}
}
]
}
}
}
}
]
}
}
}
The response JSON will contain three documents with black or 512GB in their facets:
| id | name | facets |
|---|---|---|
| 4 | Phone 4 | (Black, Blue), (256GB, 512GB) |
| 1 | Phone 1 | (Black), (128GB) |
| 3 | Phone 3 | (Black, Red), (128GB, 256GB) |
Notice that Phone 4 appears at the top of the results as it matches both conditions (black and 512GB), whereas the other phones match only one.
This is because we used the must clause instead of filter.
While both must and filter restrict results to documents matching all specified queries, must also considers scoring when ranking results.
In contrast, filter ignores scoring altogether.
Conjunctive facets + disjunctive facets
You can also combine conjunctive facets and disjunctive facets.
Here’s the query DSL that searches documents whose color is either black or red and capcity is 128GB.
In other words, (color: black or red) and (capacity: 128GB).
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "1"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"1",
"2"
]
}
}
}
}
]
}
}
}
},
{
"nested": {
"path": "facets",
"query": {
"bool": {
"must": [
{
"term": {
"facets.code": "2"
}
},
{
"nested": {
"path": "facets.values",
"query": {
"terms": {
"facets.values.code": [
"1"
]
}
}
}
}
]
}
}
}
}
]
}
}
}
The response JSON will contain two documents that match the condition:
| id | name | facets |
|---|---|---|
| 1 | Phone 1 | (Black), (128GB) |
| 3 | Phone 3 | (Black, Red), (128GB, 256GB) |
Conclusion
The method outlined in this post is just one of many approaches to building faceted search. There may be better designs and tools depending on your specific use cases and the unique needs of your users. Ultimately, with the right approach and tools, such as Elasticsearch, you can create an intuitive and efficient search system that can significantly enhances the user experience of any search-driven application.