
Redlock: Distributed Lock Manager with Redis
A couple years ago, I discovered an issue caused by a race condition that occured in the backend application I was maintaining. So I implemented a simple distributed lock using Redis as a concurrency control mechanism. And then afterwards, I found an article about Redlock algorithm, one of the DLM (Distributed Lock Manager) implementations with Redis.
This post is a walk-through of Redlock with Python.
Context
I am developing a REST API application that connects to a database. The application runs on multiple workers or nodes - they are distributed. It turns out that race conditions occur from time to time as the number of requests is increasing. While there are some solutions to deal with this problem, I decide to implement a distributed lock to coordinate the concurrent accesses to the database.
Example
The example application that can lead us to concurrency problems:
from time import sleep
from fastapi import FastAPI, status
from fastapi.exceptions import HTTPException
from pydantic import BaseModel
app = FastAPI()
items: list = [] # Database
MAX_ITEM_NUM = 3
class ItemCreate(BaseModel):
name: str
@app.post("/items", status_code=status.HTTP_201_CREATED)
def create_item(item_in: ItemCreate):
num_items = len(items) # 1. Get the current number of items.
if MAX_ITEM_NUM <= num_items: # 2. Check if it's okay to create more item.
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=f"Cannot create more than {MAX_ITEM_NUM} items.",
)
sleep(0.1) # 3. Do some other tasks.
items.append(item_in.name) # 4. Commit the transaction.
return {"items": items, "total": len(items)}
You might think of items as just a representation of any external database such as PostgreSQL, MySQL and whatnot.
I also add sleep() to simulate the real-world delay that any business process can incur.
The longer the delay, the more likely it is vulnerable to concurrency problems because there’s more chance of executing the same context in a parallel manner.
To simulate the problem, you can run the application on multiple processes with a load balancer.
But for simplicity, you can just deploy it in a single process, because FastAPI, by default, uses a threadpool to handle requests if a path operation function is declared with normal def.
For the test, the client will send 5 requests concurrently and then log the status code and the response body.
The name of the item is just the sequence of the request.
And the result of the test is:
201 - {'items': ['2', '1', '0', '4', '3'], 'total': 4}
201 - {'items': ['2', '1', '0', '4', '3'], 'total': 1}
201 - {'items': ['2', '1', '0', '4', '3'], 'total': 2}
201 - {'items': ['2', '1', '0', '4', '3'], 'total': 3}
201 - {'items': ['2', '1', '0', '4', '3'], 'total': 5}
The results may vary every time you run the test due to the nature of multithreading. As a matter of fact, there are multiple factors that affect the result in concurrent systems. They are schedulers, network delay, and many others. I won’t get into detail since it’s a bit out of the scope of this post.
What happened is that every request has passed through the conditional statement because num_items would still be 0 before committing the first transaction.

Problem
How to implement distributed locks?
Solution
Version 0
A naive implementation would look like this:
from time import sleep
from random import uniform
from contextlib import contextmanager
from fastapi import FastAPI, status
from fastapi.exceptions import HTTPException
from pydantic import BaseModel
from redis import Redis
app = FastAPI()
items: list = []
MAX_ITEM_NUM = 3
class ItemCreate(BaseModel):
name: str
r = Redis(host="localhost", port="6379", db=0)
@contextmanager
def lock(name: str):
try:
while True:
_lock = r.get(name=name) # 1. Get a lock value.
if _lock: # 2. Check if the lock is free.
sleep(uniform(0.1, 0.2)) # Wait to retry.
continue
break
r.set(name=name, value=b"1") # 3. Acquire the lock.
yield # 4. Execute the critical section.
finally:
r.delete(name) # 5. Release the lock.
@app.post("/items", status_code=status.HTTP_201_CREATED)
def create_item(item_in: ItemCreate):
with lock(name="create_item"):
num_items = len(items)
if MAX_ITEM_NUM <= num_items:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=f"Cannot create more than {MAX_ITEM_NUM} items.",
)
sleep(0.1)
items.append(item_in.name)
return {"items": items, "total": len(items)}
This example is just to help anyone who is not familiar with the basic concept of distributed lock mechanism.
The lock function does:
- Get a lock value.
- Check if the lock is free and wait to retry for a moment if it’s not available.
- Acquire the lock.
- Execute the critical section wrapped around by its context manager.
- Release the lock.
This way, the application now serializes the requests. Only the client that has a lock can proceed the transaction, forcing all the threads handle multiple concurrent requests one at a time.
Note that there is a short random delay before retrying for the lock. This is to prevent the excessive retries and multiple clients retrying for the lock at the same time.
The logic might seem correct at first glance, but we can easily expect a few problems with this implementation. The obvious one is a deadlock. If any of the incoming requests fails to release the lock, the other clients must be waiting forever until that lock is available. The other one is the delay between checking and setting the lock value. Although it would be just a very short moment, here’s what happens with 5 concurrent requests:
201 - {'items': ['1', '3', '4', '2', '0'], 'total': 5}
201 - {'items': ['1', '3', '4', '2', '0'], 'total': 5}
201 - {'items': ['1', '3', '4', '2', '0'], 'total': 5}
201 - {'items': ['1', '3', '4', '2', '0'], 'total': 5}
201 - {'items': ['1', '3', '4', '2', '0'], 'total': 5}
Let’s see how we can improve this.
Version 1
The example below is considered a correct implementation with a single node:
...
from os import urandom
...
UNLOCK_SCRIPT = """
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
"""
@contextmanager
def lock(name: str, timeout: int = 3):
try:
value = urandom(20) # Generate a random value
# Acquire the lock only if it is free
while r.set(name=name, value=value, ex=timeout, nx=True) is not True:
sleep(uniform(0.1, 0.2))
yield
finally:
# Release the lock only if it was created by the same client
r.eval(UNLOCK_SCRIPT, 1, name, value)
...
There are a few improvements to the previous example.
- Deadklock problem is removed simply by adding a timeout.
- The delay bewteen checking and setting the lock is greatly reduced by using
SETNX(SET if Not eXists) interface of Redis that allows to set the value only if it does not exist. - The risk of unwanted lock releases when a client with a lock gets blocked longer than the lock validity time is eliminated by identifying the random strings before releasing the lock.
The result of 5 concurrent requests is as follows:
201 - {'items': ['3'], 'total': 1}
201 - {'items': ['3', '2'], 'total': 2}
201 - {'items': ['3', '2', '0'], 'total': 3}
400 - {'detail': 'Cannot create more than 3 items.'}
400 - {'detail': 'Cannot create more than 3 items.'}
The diagram below is to illustrate what happens in this test:
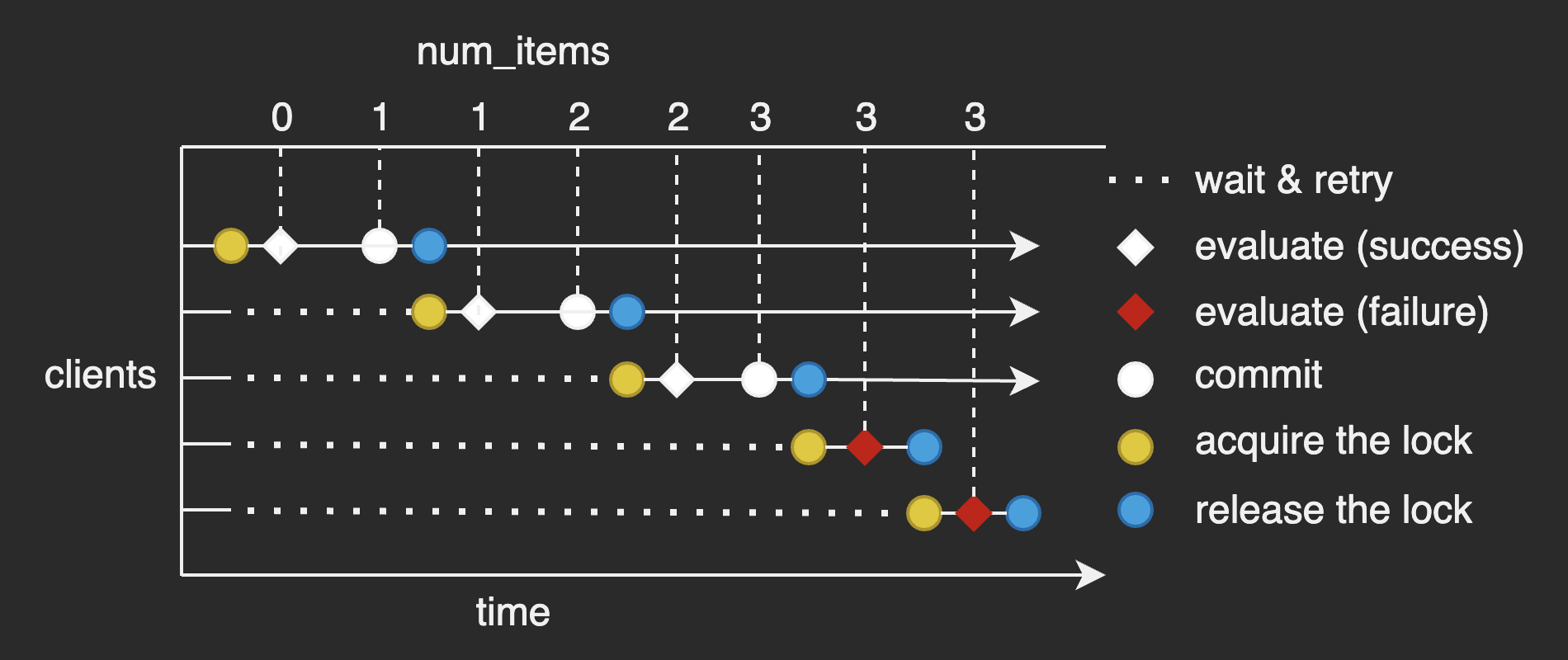
The mechanism here is what Redlock is based on.
Version 2 (Redlock)
Basically, Redlock requires at least 3 Redis instances to avoid a single point of failure. By doing so, Redlock provides better guarantees on availability with some extra cost.
The example Redlock with 3 instances is as follows:
from time import sleep, time
from random import uniform
from contextlib import contextmanager
from os import urandom
from fastapi import FastAPI, status
from fastapi.exceptions import HTTPException
from pydantic import BaseModel
from redis import Redis
from redis.exceptions import RedisError
app = FastAPI()
items: list = []
MAX_ITEM_NUM = 3
class ItemCreate(BaseModel):
name: str
servers = []
for url in [
"redis://localhost:6379",
"redis://localhost:6380",
"redis://localhost:6381",
]:
servers.append(Redis.from_url(url))
quorum = (len(servers) // 2) + 1
UNLOCK_SCRIPT = """
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
"""
@contextmanager
def lock(name: str, timeout: int = 3):
value = urandom(20)
while True:
num_acquired = 0
# 1. Get the current time in milliseconds.
start_at = int(time() * 1000)
# 2. Try to acquire the lock in all the instances.
for server in servers:
try:
if server.set(name, value, nx=True, ex=timeout):
num_acquired += 1
except RedisError as e:
pass
# 3. Get the elapsed time to acquire the lock.
elapsed = int(time() * 1000) - start_at
# 4. If lock is acquired, do the task and unlock all the instances.
if quorum <= num_acquired and elapsed < timeout * 1000:
try:
yield
finally:
for server in servers:
try:
server.eval(UNLOCK_SCRIPT, 1, name, value)
except RedisError as e:
pass
break
# 5. Unlock all the instances if the client failed to acquire the lock.
for server in servers:
try:
server.eval(UNLOCK_SCRIPT, 1, name, value)
except RedisError as e:
pass
sleep(uniform(0.1, 0.2))
@app.post("/items", status_code=status.HTTP_201_CREATED)
def create_item(item_in: ItemCreate):
with lock(name="create_item"):
count = len(items)
if MAX_ITEM_NUM <= count:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=f"Cannot create more than {MAX_ITEM_NUM} items.",
)
sleep(0.1)
items.append(item_in.name)
return {"items": items, "total": len(items)}
The comments I added in the code were simply just copied from the original article I linked in the intro.
Aside from them, the overall operation can be summarized as the following steps:
- Try to acquire the lock in all the instances sequentially.
- Check if the lock is acquired. The lock is considered acquired only if:
- The elapsed time to acquire the lock is less than lock validity time.
- The key was set in the majority of the instances.
- Do the task if the lock is acquired.
- Unlock all the instances whether or not it acquired the lock.
The rationales behind the two conditions for lock acquisition are as follows:
- If the elapsed time is longer than the lock validity time, the other client will be able to acquire the lock.
- Locking the majority of the instances ensures only one client can claim the lock so that no other client can acquire the lock.
Now, this version can survive from the single point of failure.
What else should we care about?
Version 2.1
A few improvements were made in our last version:
...
@contextmanager
def lock(name: str, timeout: int = 3, max_retries: int = 5):
value = urandom(20)
retry = 0
clock_drift = 5 # milliseconds
# Break out of the while loop if the majority of the instances are down.
while retry < max_retries:
num_acquired = 0
start_at = int(time() * 1000)
for server in servers:
try:
if server.set(name, value, nx=True, ex=timeout):
num_acquired += 1
except RedisError as e:
pass
elapsed = int(time() * 1000) - start_at
# Make sure ...
if quorum <= num_acquired and elapsed + clock_drift < timeout * 1000:
try:
yield
finally:
for server in servers:
try:
server.eval(UNLOCK_SCRIPT, 1, name, value)
except RedisError as e:
pass
break
for server in servers:
try:
server.eval(UNLOCK_SCRIPT, 1, name, value)
except RedisError as e:
pass
sleep(uniform(0.1, 0.2))
retry += 1
# Do the task even if it failed to acquire the lock.
if max_retries <= retry:
yield
...
One change is that we have max_retries to limit the number of tries.
Although the previous version is free from a SPOF, we should not ignore the case where the majority or all of the instances were down.
In that case, the client would be locked into the while loop trying to acquire the lock until the required number of instances get back to normal.
The other change is that we add clock_drift to tighten one of the conditions for lock acquisition - “the elapsed time must be less than the lock validity time”.
Because Redlock sets the key to each instance sequentially, the keys will expire at different times.
It means that the practical lock validity time is not exactly equal to the key expiration time.
The discrepancy should be trivial if there are not many Redis instances and network delay is nothing to worry about.
But we can still improve correctness by narrowing down the lock validity time by a few milliseconds.
You may copy the code in this example and use it directly in your project. But I recommend you use the other well-organized Redlock libraries such as Redlock-py or Pottery.
Opinion
So, is Redlock always a better solution over the single-redis lock? The trade-off is obvious - cost or availability. In my opinion, the single-redis approach would be enough for cases where it’s okay to ignore the problem for whatever reason. I want to point out that the number of Redis instances of Redlock are at least three times bigger than of a single redis. I don’t deem this extra(vagant) cost of Redlock is worth the better availability if the problem is not so critical and rarely occurs.
As I mentioned earlier in this post, this is just a walk-through of Redlock, not an analysis. For a detailed analysis and criticism also, refer to this article by Martin Kleppmann, a researcher of distributed systems. Martin criticizes that Redlock is not suitable for problems where correctness is of the essence due to its dangerous assumptions about timing. Instead, he recommends we use a consensus system such as Zookeeper for that purpose. He also recommends sticking with the single-node Redis for non-critical purposes, as I thought the same.