
Scheduling
A CPU scheduler is an operating system module that decides which process in the ready queue is allocated a CPU. It checks all of the tasks in the ready queue to choose the one to dispatch to the CPU.
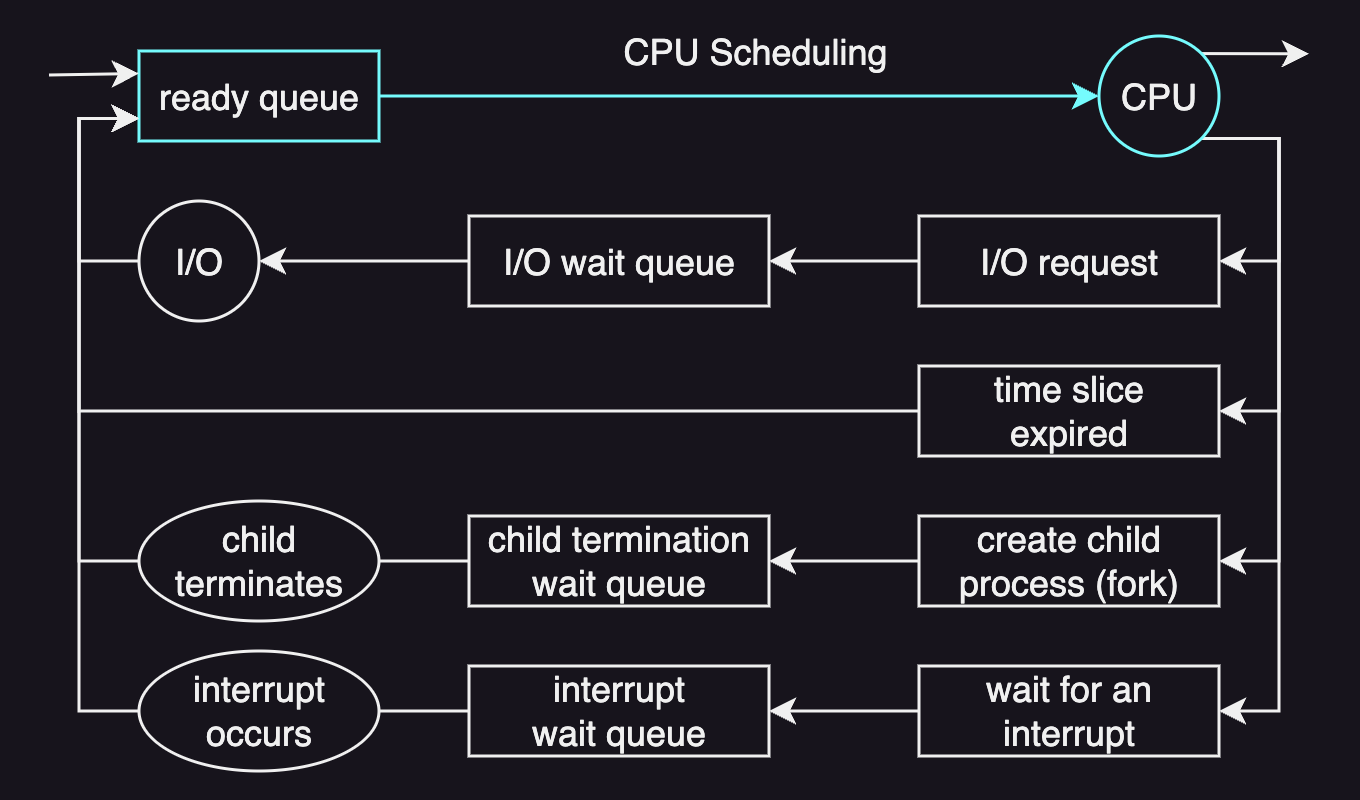
The CPU scheduler typically runs with any of the following conditions:
- the CPU becomes idle (e.g. a process makes an I/O request)
- a new task becomes ready (if the new task is of higher priority than the currently executing task, the scheduler interrupts that executing task.)
- a time slice expires
Note that the scheduling algorithm depends on the data structure of the ready queue. It means that some scheduling algorithms require a particular data structure to be supported.
Run-to-Completion (Non-preemptive) Scheduling
Run-to-completion scheduling or non-preemptive scheduling is a scheduling algorithm in which each task runs until it completes. In other words, once a task is allocated a CPU, it will not be interrupted or preempted until it finishes.
First-Come First-Serve (FCFS)
With FCFS algorithm, tasks are scheduled in the same order in which they arrive.
The data structure for this algorithm is a FIFO queue in which the scheduler can pick up the tasks in a FIFO manner.
It is the simplest CPU scheduling algorithm because the scheduler only needs to know the head of the run queue so that it can dequeue the task from it.
Shortest Job First (SJF)
With SJF algorithm, tasks are scheduled in order of their execution time.
More specifically, when the CPU is idle, the process with the smallest next CPU burst is assigned to that CPU. And if the next CPU bursts of multiple processes are the same, FCFS scheduling is used.
The data structure for this algorithm can be either a ordered queue or a tree so that the scheduler can insert the new task to the run queue to preserve the execution time in order.
One disadvantage over FCFS is that it has to predict execution time of the task before execution. For example, it predicts the execution time of a task from the average of previous execution times.
FCFS vs SJF
Assume that we have three tasks in a run queue with the following execution times:
| task | execution time |
|---|---|
| T1 | 1s |
| T2 | 10s |
| T3 | 1s |
The row order is equal to their arrival time in the run queue.
We can calculate some of the useful metrics of the two algorithms above:
| algorithm | throughput | avg. completion time | avg. wait time |
|---|---|---|---|
| FCFS | 3/(1+10+1) = 0.25tasks/s | (1+11+12)/3 = 8s | (0+1+11)/3 = 4s |
| SJF | 3/(1+1+10) = 0.25tasks/s | (1+2+12)/3 = 5s | (0+1+2)/3 = 1s |
In this particular example, we can see that SJF is more efficient than FCFS.
Preemptive Scheduling
In preemptive scheduling, an executing task can be interrupted for other tasks to be executed on the CPU.
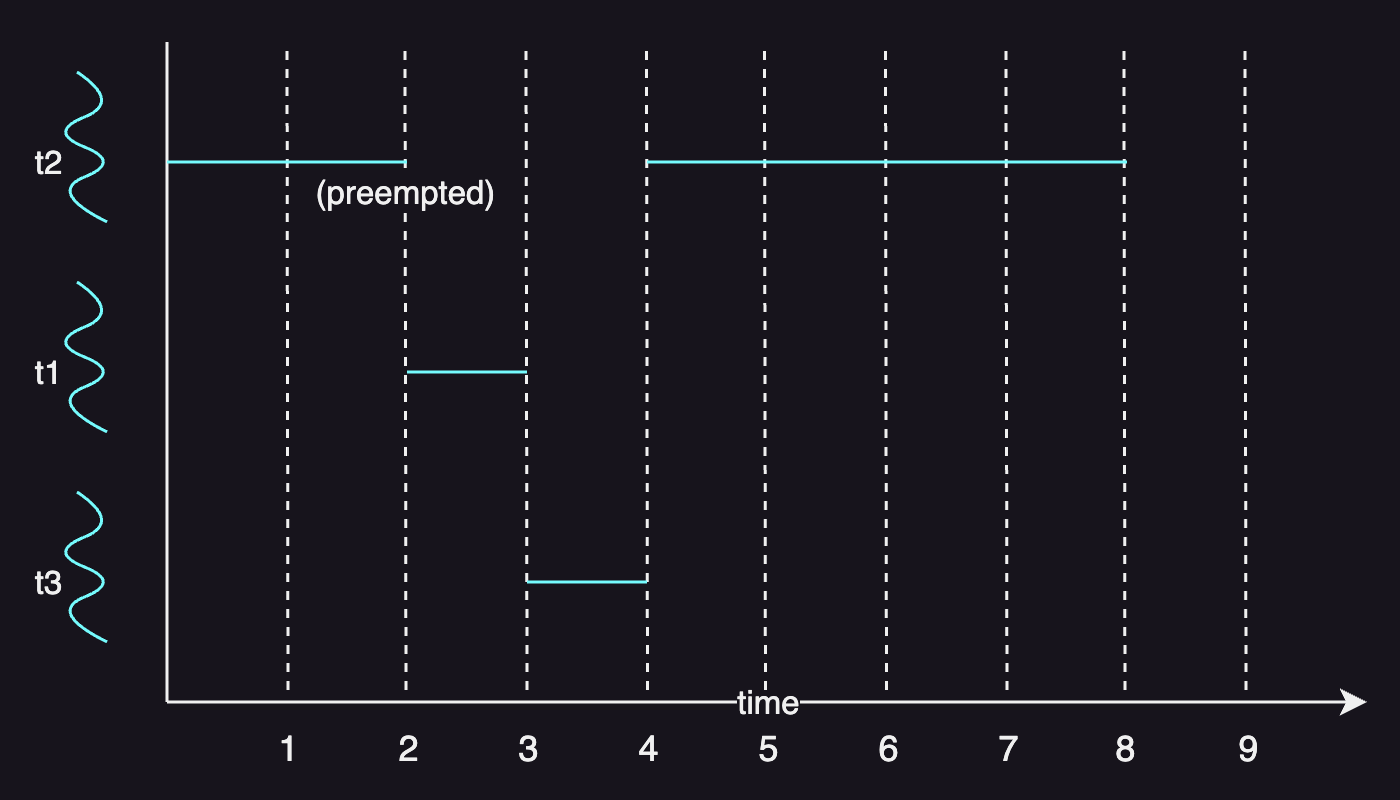
Shortest Remaining Time First (SRTF)
Shortest remaining time first (SRTF) is a preemptive version of shortest job first (SJF) scheduling.
For example, the following table shows three tasks with the execution time and arrival time:
| task | execution time | arrival time |
|---|---|---|
| T1 | 1s | 2 |
| T2 | 6s | 0 |
| T3 | 1s | 2 |
When T1 and T3 arrive, T2 should be preempted as it still has 4 seconds to be finished and both T2 and T3 have the shorter remaining time than T2 has.
Just like SJF scheduling, we don’t really know the exact execution time of a task. In practice, the scheduler has to estimate the execution time by using heuristics based on factors such as the past execution time.
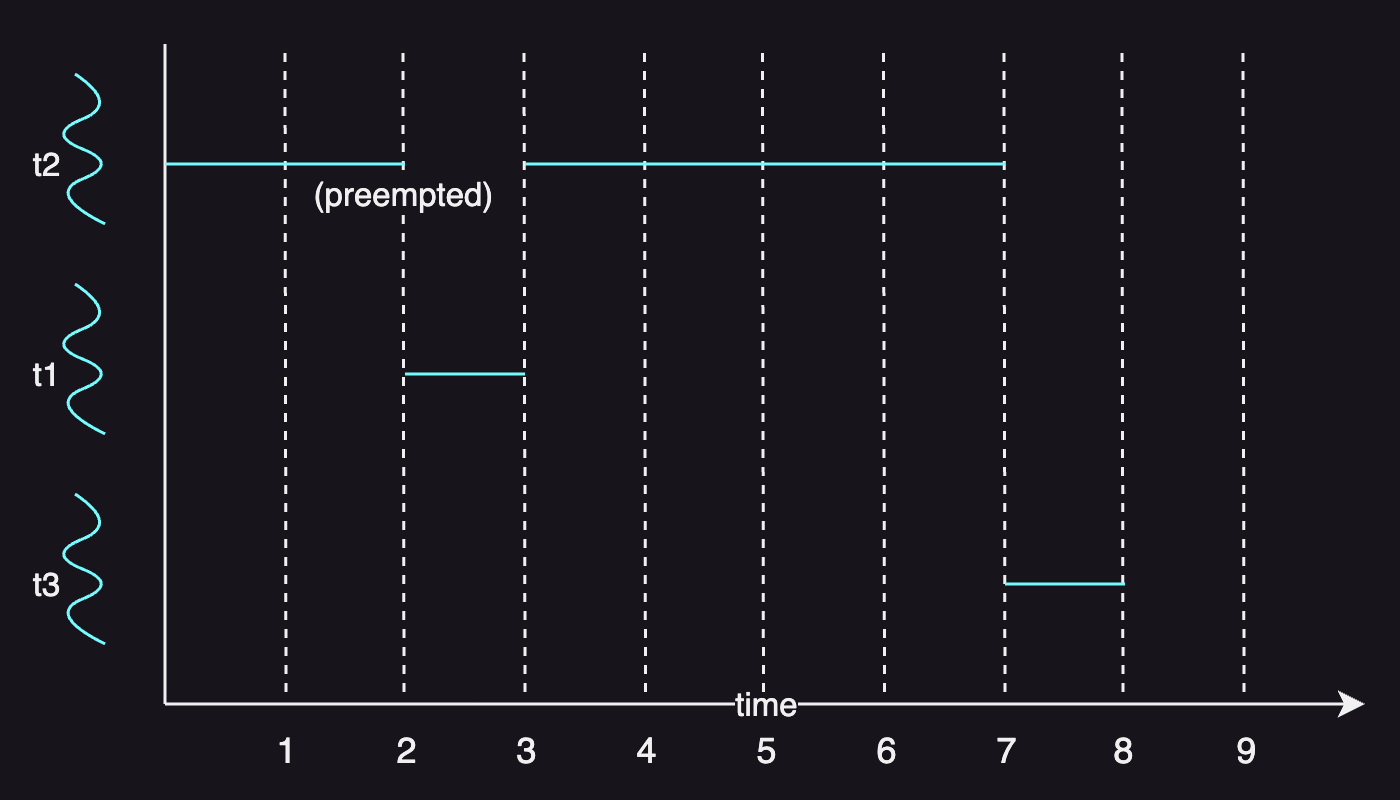
Priority
Tasks may have different priorities, and the scheduler can run the highest priority task next.
The following table adds priority levels to the same table in the previous example:
| task | execution time | arrival time | priority |
|---|---|---|---|
| T1 | 1s | 2 | 1 |
| T2 | 6s | 0 | 2 |
| T3 | 1s | 2 | 3 |
Assume that 1 is the highest priority level, the scheduler will preempt T2 and start T1 next. As T3 is of the lowest priority, it is scheduled after T2 completes its execution.
One issue with this algorithm is starvation, in which low priority tasks can be stuck in a run queue when the higher priority tasks keep arriving in the higher priority run queue. To address starvation, the scheduler can use a mechanism that updates the priority based on the time a task spent in the run queue.
Round-robin (RR)
Round-robin selects the first task in the ready queue to execute. It differs from FCFS in that tasks may yield the CPU, for example, to wait on an I/O operation.
RR can also be incorporated into priorities. With priorities, the lower priority task is preempted when a higher priority task arrives.
Timeslices
A timeslice or time quantum is the period of time for which a task is allowed to run without preemption. In other words, it is the maximum amount of uninterrupted time given to a task.
Using timeslices enables interleaving the tasks, in which the tasks can time-share the CPU.
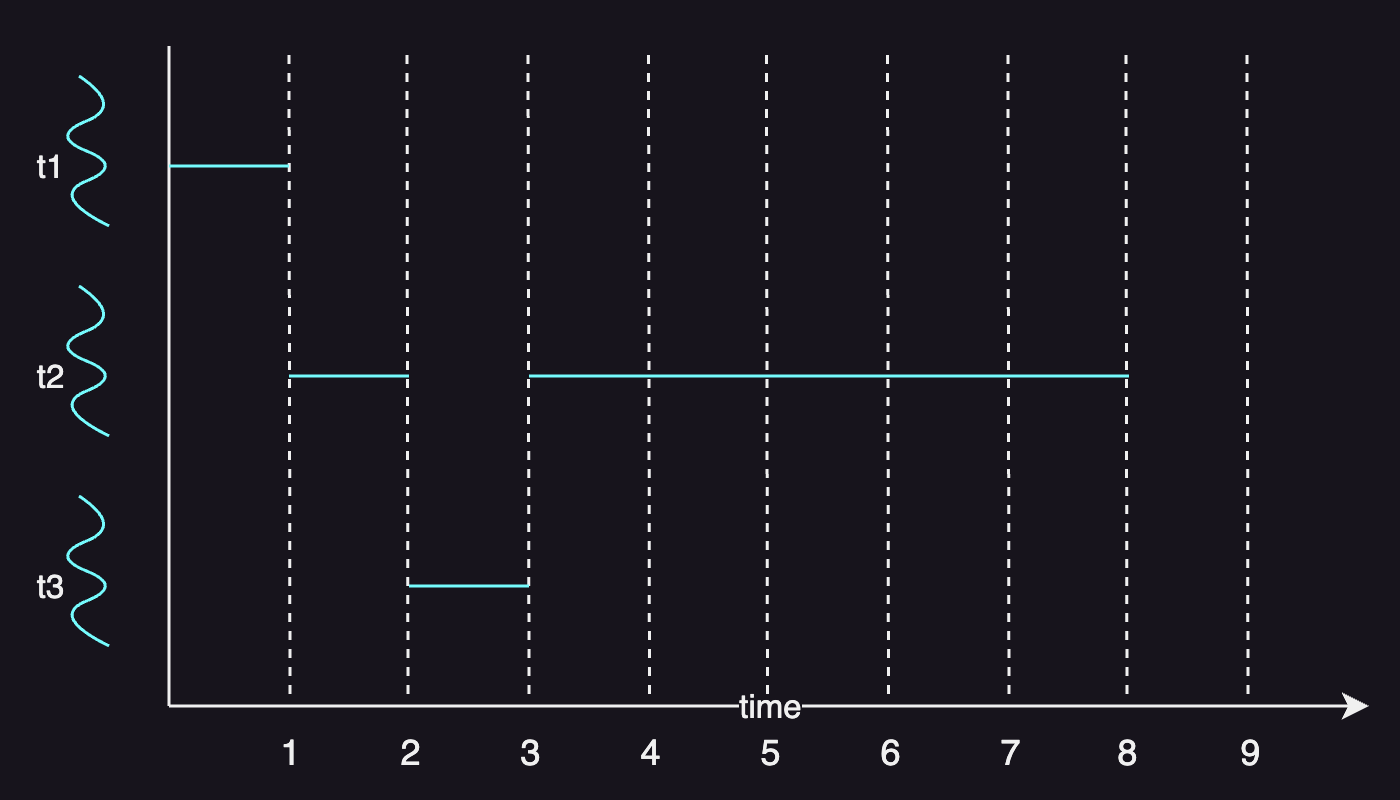
Assume that we have three tasks that arrive at the same time:
| task | execution time | arrival time |
|---|---|---|
| T1 | 1s | 0 |
| T2 | 6s | 0 |
| T3 | 1s | 0 |
With RR with 1 timeslice, T2 will be preempted after a timeslice and re-execute after T3 completes.
The same metrics we used in the previous example are as follows:
| algorithm | throughput | avg. completion time | avg. wait time |
|---|---|---|---|
| RR(ts=1) | 3/(1+6+1) = 0.375tasks/s | (0+1+2)/3 = 1s | (1+8+3)/3 = 4s |
One advantage of this approach over SJF is that it doesn’t have to predict the execution time. Another benefit is that it can execute an I/O operation within its timeslice, whereas it would have to wait if that task takes the longest time in SJF.
The drawback is the cost of context switch. And the shorter the timeslice, the higher the cost.
Do note that the optimal value of the timeslice may differ depending on whether the tasks are I/O-bound or CPU-bound. In general, choosing a larger timeslice value is better with CPU-bound tasks, and vice versa.
Multilevel Feedback Queue
A multilevel feedback queue consists of multiple ready queues, each of which has different scheduling policy levels. It is designed to make the most out of the CPU.
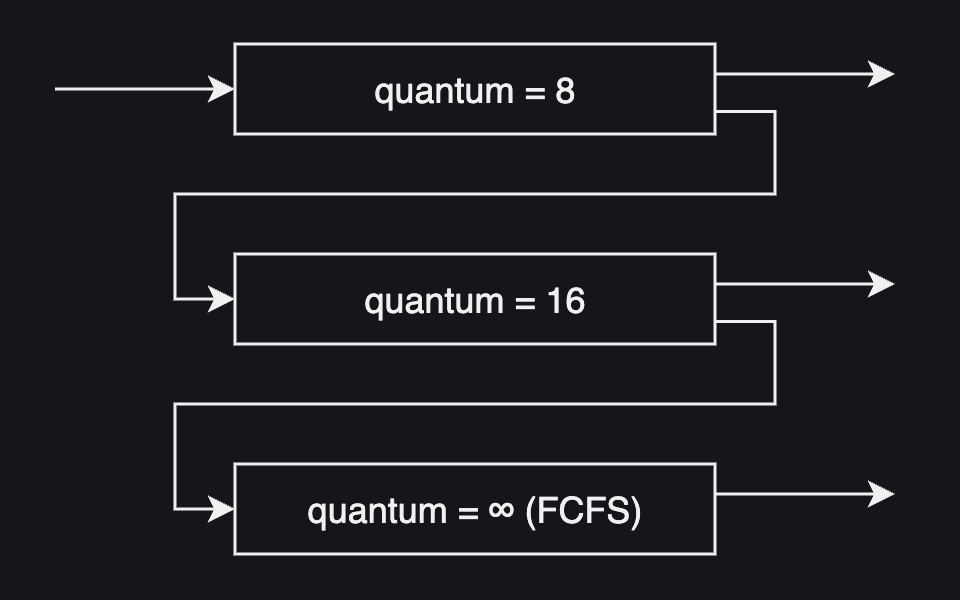
In this algorithm, a new task is put in the first queue, but it moves between queues depending on the characteristics of their CPU bursts.
For example, a task that uses much CPU time is moved to a lower-priority queue so that I/O-bound tasks with shorter CPU bursts remain in the higher-priority queues. And a task with a long waiting time in a lower-priority queue may be moved to a higher-priority queue to prevent starvation.
In general, any task with a CPU burst of 8 milliseconds or less is given the highest priority and will quickly finish its CPU burst.
O(1) Scheduler
An O(1) scheduler is based on multilevel feedback queue scheduler in that it has different quantum values with different priorty levels. It can schedule tasks within a constant amount of time, regardless of how many tasks are active in the system.
The priority levels of the Linux O(1) scheduler range from 0 the highest to 139 the lowest, and each priority level has its own quantum value. And real-time tasks have a priority level in the range from 0 to 99, while user tasks do in the range from 100 to 139.
| priority | quantum value | type of tasks |
|---|---|---|
| 0 | 200ms | real-time tasks |
| … | … | … |
| 99 | … | real-time tasks |
| 100 | … | user tasks |
| … | … | … |
| 139 | 10ms | user tasks |
The scheduler assigns high timeslices to the more interactive high priority tasks. One feedback mechanism for this priority adjustment is that it boosts the priority of a task that has a longer sleep time, as that task is likely to be more interactive. On the other hand, a task with a shorter sleep time is considered as more CPU-bound and its priority is lowered.
The runqueue has 2 arrays of tasks - active array and expired array, each array had 140 priorities. And each entry in an array points to the first task of a linked list of the tasks.
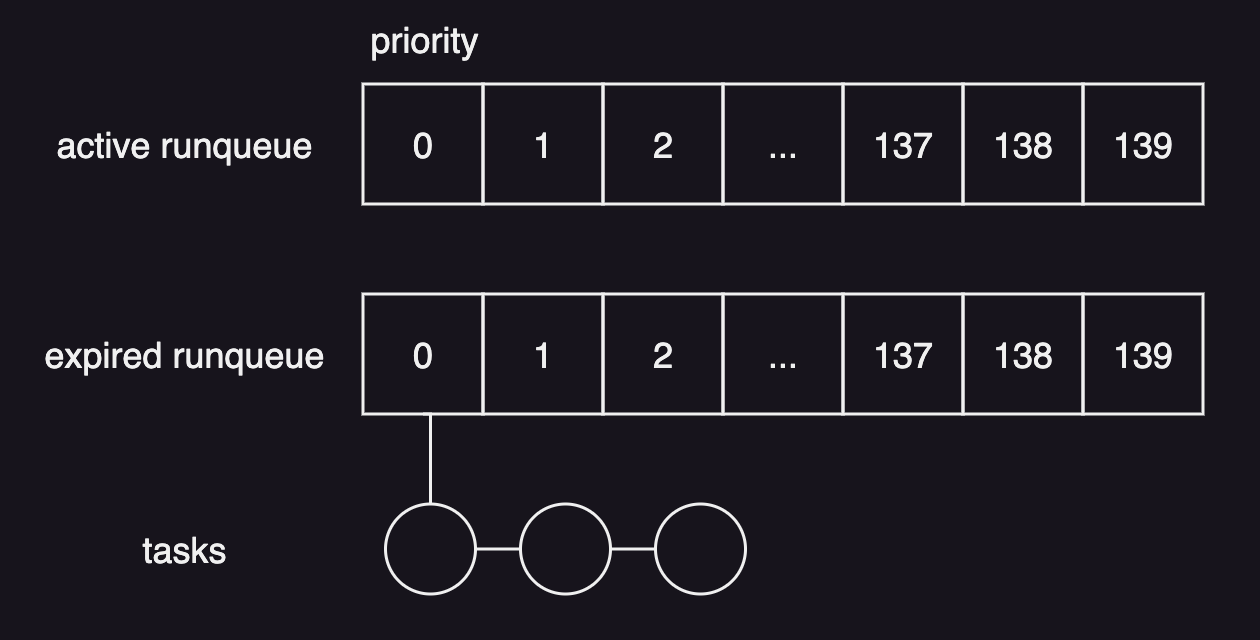
The scheduler uses the active list to pick the next task to run and it allows the scheduler to take constant time to select a task.
Once a timeslice of a task expires, the task is moved from the active list into the appropriate task list in the expired array. The tasks in the expired array are inactive and not scheduled until the active array becomes empty. When the active array has no more tasks, the pointers of two arrays are swapped so that the expired array becomes the active array.
One issue with this algorithm is that it does not guarantee any fairness. it means that an amount of time for a task to run is not really proportional to its priority.
This scheduler was replaced by the Completely Fair Scheduler in Linux 2.6.23 (2007), as interactive workloads were becoming more general and the O(1) scheduler was not efficient enough for that purpose.
Completely Fair Scheduler (CFS)
The Completely Fair Scheduler, the default scheduler for non-real time tasks in Linux, allocates a proportion of the CPU time to each task rather than time slices, based on the vruntime(virtual runtime) value which is the amount of time a task spent on the CPU.
It uses a red-black tree as a runqueue structure whose key is based on the vruntime.
And a task is added to the tree when it becomes runnable, and it is removed from the tree when it is not runnable.
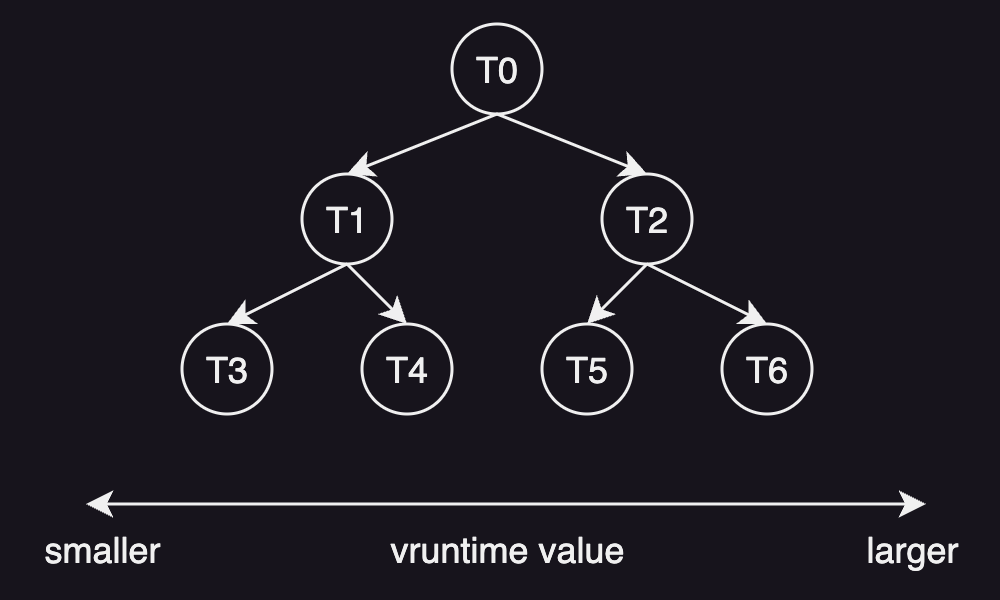
As seen in the figure above, the leftmost task in the tree has the smallest vruntime value and has the highest priority, which is the next task to run.
The tasks on the right side of the tree have spent more vruntime so that they don’t get scheduled as quickly as the ones of the left side of the tree.
When a task is running on the CPU, the CFS periodically increments the vruntime of that task and compares it to the vruntime of the leftmost task in order to decide whether to preempt the currently running task and context switch to the leftmost task.
Note that while the time complexity of finding the leftmost node is O(log N) operations when N is the number of nodes in the tree, the actual implementation in the Linux simply caches it to quickly pick the next task to run. Adding a node takes O(log N) time, which is considered acceptable for most modern systems.
Scheduling on Multiprocessors
Scheduling on multiprocessors is complex and there is no one best solution.
Two approaches to CPU scheduling in a multiprocessor system are:
- asymmetric multiprocessing: all scheduling decisions are handled by a single processor - the master server.
- symmetric multiprocessing (SMP): each processor is self-schedulding.
While the asymmetric multiprocessing is simple as only core is responsible for all scheduling decisions, there is a possibility that the master server becomes the performance bottleneck. For that reason, symmetric multiprocessing is the standard approach for this problem.
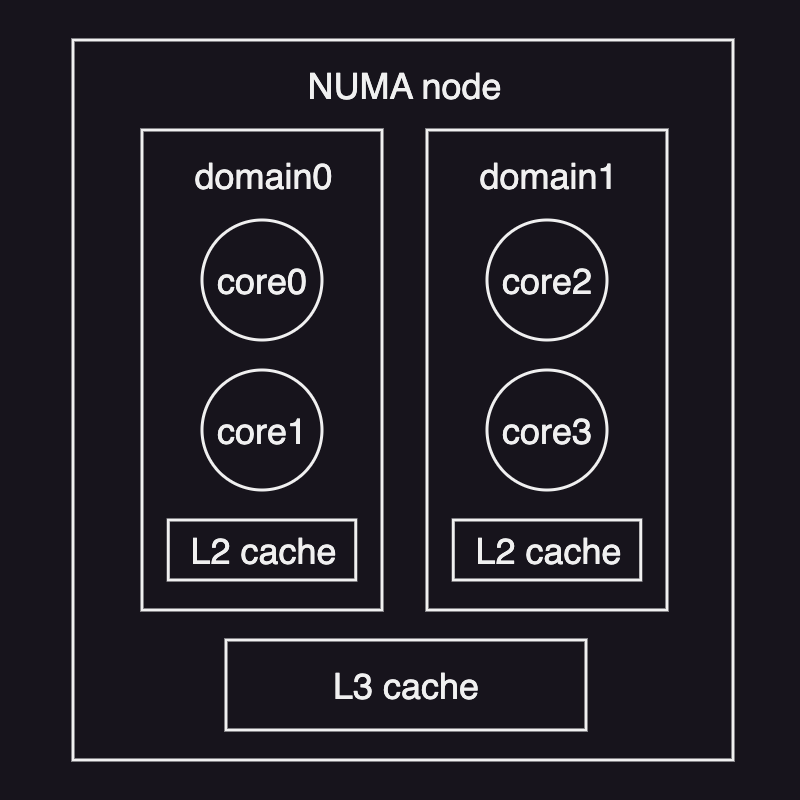
One important consideration when scheduling on multiprocessor system is cache affinity. If a particular task or thread was executing on a particular processor or CPU, it is likely that the state of the task still resides in the cache memory of that same processor. Therefore, it helps with the performance if the task is scheduled on the same processor on which the task was executed before.
With multiple memory nodes, the general solution to achieve cache affinity is to load balance tasks in a way that tasks are bound to the processors that are closer to the memory node where their state is. This is called NUMA-aware scheduling, where NUMA stands for Non-Uniform Memory Access.
Hyperthreading
Hyperthreading is Intel’s multithreading implementation for assigning multiple hardware threads to a single core.
It is also known as:
- hardware multithreading
- chip multithreading (CMT)
- simultaneous multithreading (SMT)
For example, if a physical core supports two hardware threads (or two virtual cores), from an operating system perspective, this one physical core is recognized as two processors. This so-called multicore processor is faster and more energy-efficient than a single-core processor.
With hyperthreading, if one hardware thread is on memory stall, where a processor is waiting for the data to become available when it accesses memory, the core can context switch to another software thread.
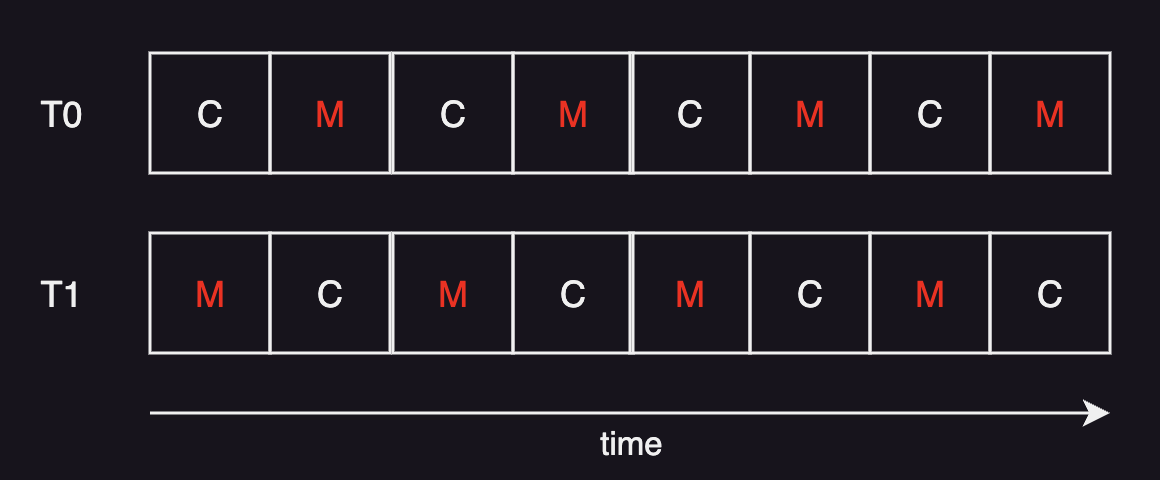
Note that a processing core can only execute one hardware thread at a time because its processor pipeline must be shared among its hardware threads. Therefore, co-scheduling of compute-bound and memory-bound threads can best benefit from this multi-core processor.